






赛题背景
金融领域交互式自证业务中涵盖信用成长、用户开户、商家入驻、职业认证、商户解限等多种应用场景,通常都需要用户提交一定的材料(即凭证)用于证明资产收入信息、身份信息、所有权信息、交易信息、资质信息等,而凭证的真实性一直是困扰金融场景自动化审核的一大难题。随着数字媒体编辑技术的发展,越来越多的AI手段和工具能够轻易对凭证材料进行篡改,大量的黑产团伙也逐渐掌握PS、AIGC等工具制作逼真的凭证样本,并对金融审核带来巨大挑战。
赛题任务
在本任务中,要求参赛者设计算法,找出凭证图像中的被篡改的区域。
语义分割与实例分割模型
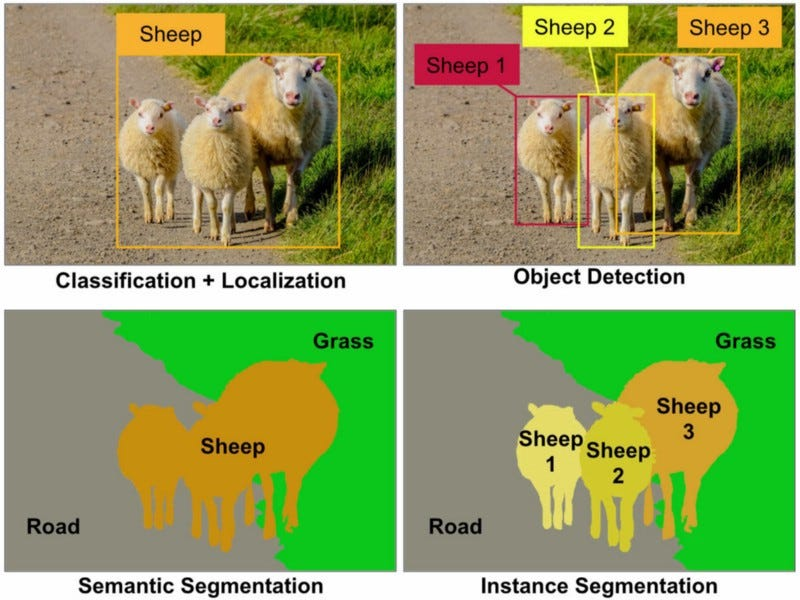
语义分割和实例分割都是计算机视觉领域中的对象识别任务,它们的目标是识别并理解图像中的内容。简单来说,语义分割关注的是“这是什么”,而实例分割关注的是“这是什么”以及“这是哪一件”。实例分割比语义分割更复杂,因为它需要更多的上下文信息来区分不同的实例。
- 语义分割(Semantic Segmentation):将图像中的每个像素分配给一个类别标签,从而识别出图像中所有对象的类别。
- 实例分割(Instance Segmentation):不仅要识别图像中的对象类别,还要区分同一类别中的不同实例
解题思路
赛题是一个典型的计算机视觉问题,涉及到图像处理和模式识别。赛题需要识别和定位图像中被篡改的区域。
- 物体检测模型:可以将篡改区域视为需要检测的“物体”。使用像Faster R-CNN或YOLO这样的物体检测模型,可以定位图像中的不同区域,并判断这些区域是否被篡改。
- 语义分割模型:语义分割模型可以将图像中的每个像素分配给一个类别,这可以用来识别图像中的篡改区域。U-Net、DeepLab或Mask R-CNN是常用的语义分割模型。

赛题提交要求
- 训练集数据总量为100w,提供篡改后的凭证图像及其对应的篡改位置标注,标注文件以csv格式给出,csv文件中包括两列,内容示例如下:
| Path | Polygon |
| 9/9082eccbddd7077bc8288bdd7773d464.jpg | [143, 359], [432, 359], [437, 423], [141, 427] |
- 测试集分为A榜和B榜,分别包含10w测试数据。测试集中数据格式与训练集中一致,但不包含标注文件。 比赛期间,参赛队伍通过天池平台下载数据,本地调试算法,在线提交结果,结果文件命名为”参赛队名称-result.csv”,包含”Path”和”Polygon”列,”Polygon”列中采用轮廓点的方式存储每个篡改区域的位置,每个区域包含[左上,右上,右下,左下]4个点的坐标。例如:
| Path | Polygon |
| 0/0aeaefa50ac1e39ecf5f02e4fa58a6a2.jpg | [139, 48], [181, 48], [181, 66], [139, 66] |
baseline
clone数据集与标程
git lfs install
git clone https://www.modelscope.cn/datasets/Datawhale/dw_AI_defense_track2.git
步骤1:准备工作
升级与下载数据
!apt update > /dev/null; apt install aria2 git-lfs axel -y > /dev/null
!pip install ultralytics==8.2.0 numpy pandas opencv-python Pillow matplotlib > /dev/null
!axel -n 12 -a http://mirror.coggle.club/seg_risky_testing_data.zip; unzip -q seg_risky_testing_data.zip
!axel -n 12 -a http://mirror.coggle.club/seg_risky_training_data_00.zip; unzip -q seg_risky_training_data_00.zip
这段代码主要用于环境设置和数据下载解压。以下是每一部分的作用解释:
!apt update > /dev/null; apt install aria2 git-lfs axel -y > /dev/nullapt update: 更新 Ubuntu 或其他基于 Debian 的系统的包索引。apt install aria2 git-lfs axel -y: 安装三个工具:- aria2:一个用于高速下载的工具,支持多种协议(HTTP、FTP、BitTorrent等)。
- git-lfs:Git Large File Storage,用于处理 Git 仓库中的大文件。
- axel:另一个加速下载的工具,支持多线程下载。
> /dev/null: 将输出重定向到空设备(即抑制命令输出显示)。
!pip install ultralytics==8.2.0 numpy pandas opencv-python Pillow matplotlib > /dev/null- 使用
pip安装一组 Python 库:- ultralytics==8.2.0:Ultralytics 是 YOLO 系列目标检测模型的实现,这里安装的是特定版本 8.2.0。
- numpy:用于科学计算的库,特别是矩阵运算。
- pandas:用于数据处理和分析的库,擅长处理表格型数据。
- opencv-python:OpenCV 的 Python 绑定,用于图像处理和计算机视觉任务。
- Pillow:Python 的图像处理库。
- matplotlib:用于生成图形和可视化数据。
> /dev/null:同样将输出重定向到空设备以抑制命令输出。
- 使用
!axel -n 12 -a http://mirror.coggle.club/seg_risky_testing_data.zip; unzip -q seg_risky_testing_data.zipaxel -n 12 -a URL: 使用axel工具通过 12 个线程来加速下载seg_risky_testing_data.zip文件。-n 12表示并发使用 12 条连接,-a表示显示下载进度。unzip -q seg_risky_testing_data.zip: 解压下载的压缩文件seg_risky_testing_data.zip,-q选项用于静默模式,不显示解压进度。
!axel -n 12 -a http://mirror.coggle.club/seg_risky_training_data_00.zip; unzip -q seg_risky_training_data_00.zip- 同样的操作步骤:使用
axel加速下载名为seg_risky_training_data_00.zip的训练数据文件,并解压它。
- 同样的操作步骤:使用
总结:
这段代码的作用是:
- 安装必要的下载工具(
aria2,git-lfs,axel)和机器学习库(ultralytics、numpy等)。 - 从网络上下载两个数据集(用于测试和训练的压缩数据),并解压这些数据集,以便接下来进行机器学习或图像处理任务。
文件处理
import os, shutil
import cv2
import glob
import json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
training_anno = pd.read_csv('http://mirror.coggle.club/seg_risky_training_anno.csv')
train_jpgs = [x.replace('./', '') for x in glob.glob('./0/*.jpg')]
training_anno = training_anno[training_anno['Path'].isin(train_jpgs)]
training_anno['Polygons'] = training_anno['Polygons'].apply(json.loads)
training_anno.head()
这部分代码用于数据准备和处理,特别是图像文件及其相关的标注(annotations)信息。它读取了训练图像文件和相应的标注数据,进行一些过滤和处理。以下是每一部分的详细解释:
- 导入必要的库
import os, shutil # 操作系统和文件管理
import cv2 # OpenCV库,用于图像处理
import glob # 用于查找匹配文件路径
import json # 用于处理JSON格式数据
import pandas as pd # 用于数据处理,特别是CSV文件
import numpy as np # 数组和矩阵计算
import matplotlib.pyplot as plt # 用于数据可视化
这部分代码导入了几个常用的库:
- os 和 shutil:用于操作文件和目录,比如文件移动、删除等。
- cv2:OpenCV库,用于读取和处理图像。
- glob:用于查找符合特定模式的文件名,返回文件路径的列表。
- json:用于处理JSON格式的字符串(如解析标注数据)。
- pandas:用于读取和处理CSV文件、数据操作。
- numpy:用于高效的数组计算和数据处理。
- matplotlib:用于生成图表和可视化数据。
- 读取标注文件
training_anno = pd.read_csv('http://mirror.coggle.club/seg_risky_training_anno.csv')
这行代码从指定的URL中读取一个CSV文件,加载为一个Pandas的DataFrame对象。这个CSV文件应该包含与训练图像对应的标注数据,通常用于图像分割、检测任务。标注文件可能包含图像路径及其对应的标注(如多边形区域、标签等)。
- 读取训练图像文件名
train_jpgs = [x.replace('./', '') for x in glob.glob('./0/*.jpg')]
这里使用 glob 函数查找当前目录下 ./0/ 文件夹中的所有 .jpg 文件(即训练图像)。返回的列表中每个元素是文件路径名。为了与标注数据匹配,replace('./', '') 用于去掉文件路径前面的 './',得到一个仅包含文件名的列表。
- 过滤标注数据
training_anno = training_anno[training_anno['Path'].isin(train_jpgs)]
这行代码通过过滤标注数据,确保只保留那些路径与 train_jpgs 列表中的图像文件名相匹配的标注。
training_anno['Path'] 是 CSV 中的一列,包含图像文件的路径信息,isin(train_jpgs) 用于判断每个标注的图像路径是否存在于 train_jpgs 列表中。如果是,则保留该行数据。
- 解析标注中的多边形数据
training_anno['Polygons'] = training_anno['Polygons'].apply(json.loads)
这行代码将标注数据中的 Polygons 列中的内容从字符串形式解析为 Python 的字典或列表形式。
在标注任务中,Polygons 通常指示图像中标注区域的轮廓,多边形的坐标点可能以JSON格式存储。这里使用 json.loads 函数将字符串解析为可以直接使用的Python对象。
- 显示标注数据的前几行
training_anno.head()
这行代码输出 training_anno DataFrame 的前5行内容,用于快速查看数据的格式和内容。
总结:
这部分代码主要用于读取训练图像文件以及其对应的标注数据,完成以下步骤:
- 从CSV文件中加载标注数据。
- 根据图像文件名过滤相关的标注数据,确保标注与实际图像匹配。
- 将标注数据中的
Polygons列从字符串格式解析为Python对象,便于后续处理。 - 最终输出处理后的标注数据,用于检查数据格式。
查看结果
training_anno.shape
np.array(training_anno['Polygons'].iloc[4], dtype=np.int32)
training_anno.shape()
查看数据条数
np.array(training_anno['Polygons'].iloc[4], dtype=np.int32)
iloc 是 Pandas 中的一个索引方法,代表 “integer-location based indexing”,即基于整数位置进行索引。它允许通过行号或列号(基于整数索引)来访问 DataFrame 或 Series 中的元素。
在代码中:
np.array(training_anno['Polygons'].iloc[4], dtype=np.int32)
这里 iloc[4] 表示你想从 training_anno['Polygons'] 列中获取第 4 行的值(基于从 0 开始的整数位置)。这意味着你要访问 Polygons 列中第 5 个标注的多边形数据(因为 iloc 是 0 开始计数的)。
然后,np.array(..., dtype=np.int32) 将这个多边形数据转换为一个 NumPy 数组,并将数组的元素类型设置为 int32(32 位整数)。
例子:
假设 training_anno['Polygons'] 列是这样的:
| Path | Polygons |
|---|---|
| img1.jpg | [10, 20], [30, 40], [50, 60] |
| img2.jpg | [15, 25], [35, 45], [55, 65] |
| img3.jpg | [12, 22], [32, 42], [52, 62] |
| img4.jpg | [14, 24], [34, 44], [54, 64] |
| img5.jpg | [16, 26], [36, 46], [56, 66] |
training_anno['Polygons'].iloc[4] 会获取第 5 行的多边形数据 [[16, 26], [36, 46], [56, 66]]。
因此,这个 np.array() 操作会将这一多边形转换为 NumPy 数组,方便进一步处理。
总结:
iloc[4]获取Polygons列的第 4 个元素(第 5 行)。- 然后将该元素转换为 NumPy 数组,并指定数据类型为
int32。
显示训练集效果
idx = 23
img = cv2.imread(training_anno['Path'].iloc[idx])
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.title("Original Image")
plt.axis('off')
plt.subplot(122)
img = cv2.imread(training_anno['Path'].iloc[idx])
polygon_coords = np.array(training_anno['Polygons'].iloc[idx], dtype=np.int32)
for polygon_coord in polygon_coords:
cv2.polylines(img, np.expand_dims(polygon_coord, 0), isClosed=True, color=(0, 255, 0), thickness=2)
img= cv2.fillPoly(img, np.expand_dims(polygon_coord, 0), color=(255, 0, 0, 0.5))
plt.imshow(img)
plt.title("Image with Polygons")
plt.axis('off')
- 读取图像
idx = 23
img = cv2.imread(training_anno['Path'].iloc[idx])
这里 idx = 23 表示你要处理第 24 张图像(因为 iloc 基于0索引)。
cv2.imread(training_anno['Path'].iloc[idx]) 使用 OpenCV 的 imread 函数从文件路径读取这张图像。training_anno['Path'].iloc[idx] 提供了图像文件的路径(training_anno 中记录的路径)。
- 显示原始图像
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.title("Original Image")
plt.axis('off')
plt.figure(figsize=(12, 6)):创建一个 12 x 6 英寸大小的画布。plt.subplot(121):将画布划分为一行两列,这一部分显示的是第一个图像。plt.imshow(img):用matplotlib显示读取的原始图像。plt.title("Original Image"):设置显示图像的标题。plt.axis('off'):隐藏图像的坐标轴。
- 再次读取图像并准备绘制多边形
plt.subplot(122)
img = cv2.imread(training_anno['Path'].iloc[idx])
polygon_coords = np.array(training_anno['Polygons'].iloc[idx], dtype=np.int32)
plt.subplot(122):这部分用于在画布的第二列显示图像。- 再次使用
cv2.imread()读取相同的图像,为了在其上绘制多边形。 polygon_coords = np.array(training_anno['Polygons'].iloc[idx], dtype=np.int32):获取并解析该图像的多边形标注数据,将其转换为 NumPy 数组,数据类型为int32。Polygons包含的是标注的多边形坐标。
- 绘制多边形和填充区域
for polygon_coord in polygon_coords:
cv2.polylines(img, np.expand_dims(polygon_coord, 0), isClosed=True, color=(0, 255, 0), thickness=2)
img = cv2.fillPoly(img, np.expand_dims(polygon_coord, 0), color=(255, 0, 0, 0.5))
for polygon_coord in polygon_coords:遍历每个多边形的坐标。cv2.polylines():在图像上绘制多边形轮廓。参数解析:polygon_coord:当前多边形的坐标。np.expand_dims(polygon_coord, 0):将多边形的维度扩展一维,符合 OpenCV 函数的输入要求。isClosed=True:表示多边形是封闭的。color=(0, 255, 0):用绿色绘制多边形轮廓。thickness=2:多边形轮廓的线条粗细为 2。
cv2.fillPoly():填充多边形的内部区域。参数解析:color=(255, 0, 0, 0.5):用红色(部分透明)填充多边形区域。
- 显示带有多边形标注的图像
plt.imshow(img)
plt.title("Image with Polygons")
plt.axis('off')
plt.imshow(img):显示已经绘制了多边形的图像。plt.title("Image with Polygons"):设置标题为“Image with Polygons”。plt.axis('off'):隐藏坐标轴。
整体流程总结:
- 第一步:从数据集中读取第 24 张图像,并显示它的原始图像。
- 第二步:再次读取相同图像,获取该图像的多边形标注数据,并用绿色轮廓和红色填充绘制这些多边形。
- 第三步:将绘制了多边形的图像显示出来。
这段代码的主要目的是通过可视化的方式检查和展示图像中的标注区域(例如用于图像分割任务中的标注)。
步骤2:构建YOLO数据集
由于比赛原始数据集较大,我们采样部分数据构建训练集和验证集:
# 如果`yolo_seg_dataset`目录存在,这行代码会删除这个目录及其所有内容。`shutil.rmtree`函数用于删除非空目录。
if os.path.exists('yolo_seg_dataset'):
shutil.rmtree('yolo_seg_dataset')
os.makedirs('yolo_seg_dataset/train')
os.makedirs('yolo_seg_dataset/valid')
# 图片多边形区域归一化
def normalize_polygon(polygon, img_width, img_height):
return [(x / img_width, y / img_height) for x, y in polygon]
# 采样训练集
for row in training_anno.iloc[:10000].iterrows():
shutil.copy(row[1].Path, 'yolo_seg_dataset/train')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/train/' + row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{coord[0]:.3f} {coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 {normalized_coords}\n')
# 采用验证集
for row in training_anno.iloc[10000:10150].iterrows():
shutil.copy(row[1].Path, 'yolo_seg_dataset/valid')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/valid/' + row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{coord[0]:.3f} {coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 {normalized_coords}\n')
这段代码的作用是为一个YOLO(You Only Look Once)目标检测和分割模型准备训练集和验证集。代码的具体功能是从给定的标注数据 training_anno 中,复制图片文件并生成相应的标签文件(.txt),以便在YOLO模型的分割任务中使用。
详细说明:
- 训练集部分:
- 代码从
training_anno数据框中的前10000行(即training_anno.iloc[:10000])提取训练数据。 training_anno中每行包含一个图像的路径 (Path) 和相应的多边形标注 (Polygons)。shutil.copy(row[1].Path, 'yolo_seg_dataset/train'):将图片从原始路径复制到指定的yolo_seg_dataset/train目录下,用于训练集。cv2.imread(row[1].Path):使用 OpenCV 读取图片,并获取图片的宽度和高度(img_height, img_width),这些信息用于后续的坐标归一化。txt_filename:为每个图片生成一个相应的.txt文件,用于存储该图片对应的标签。文件名与图片名一致,只是扩展名从.jpg变成.txt。- 对每个图片的标注数据(即多边形坐标
Polygons)进行处理:normalize_polygon函数将多边形的坐标归一化到0到1之间(根据图片的宽度和高度)。- 将归一化后的坐标写入标签文件,每一行表示一个多边形,格式为:
类别ID(这里是0) 归一化后的坐标。 - 每个多边形的坐标是
x y的成对形式。
- 代码从
- 验证集部分:
- 从
training_anno的10000行到10150行(即training_anno.iloc[10000:10150])提取验证数据,处理方式与训练集基本相同。 - 将图片复制到
yolo_seg_dataset/valid目录下,生成相应的.txt文件,用于验证集。
- 从
总结:
这段代码主要用于生成YOLO分割任务所需的数据集:
- 训练集:前10000张图片及其对应的归一化标注。
- 验证集:第10000到10150张图片及其对应的归一化标注。
最终,目标是为YOLO模型提供标准的输入文件格式:每张图片一个 .jpg 文件和一个对应的 .txt 标签文件(里面包含归一化的标注坐标)。
生成配置文件
with open('yolo_seg_dataset/data.yaml', 'w') as up:
data_root = os.path.abspath('yolo_seg_dataset/')
up.write(f'''
path: {data_root}
train: train
val: valid
names:
0: alter
''')
这一部分代码的作用是生成一个 data.yaml 文件,它是YOLO(或YOLOv5等版本)模型的配置文件,用于指定训练和验证数据集的路径、类别名称等关键信息。
详细说明:
- 文件打开及写入:
with open('yolo_seg_dataset/data.yaml', 'w') as up:打开或创建一个名为data.yaml的文件,并以写模式(w)打开。data_root = os.path.abspath('yolo_seg_dataset/'):获取当前工作目录中yolo_seg_dataset/文件夹的绝对路径。绝对路径可以确保模型在不同环境中运行时能够正确找到数据集。- 使用
up.write()方法,将指定内容写入data.yaml文件。写入内容为一个多行的字符串(通过三引号'''实现)。
- 文件内容: 写入的内容如下:
path: {data_root}
train: train
val: valid
names:
0: alter
- path:设置数据集的根路径,这里使用变量
data_root(即yolo_seg_dataset/的绝对路径)。这告诉YOLO模型所有数据集都存储在这个根目录下。 - train 和 val:指定训练集和验证集的相对路径。相对路径相对于
path设置的根路径。train指定的是训练集所在的train文件夹,val指定的是验证集所在的valid文件夹。 - names:这是类别名称的定义。YOLO模型通常用于多类别检测或分割任务,这里定义了类别ID及其对应的名称:
0: alter表示类别ID为0的物体名称是 “alter”。如果有多个类别,可以继续列出,如1: another_class,依此类推。
这段代码生成了一个YOLO模型所需的 data.yaml 配置文件。该文件定义了数据集的根目录、训练集和验证集的路径,以及分类任务中使用的类别名称(这里只有一个类别:alter)。data.yaml 文件是YOLO训练过程的一个重要配置文件,用于指导模型从正确的路径加载数据,并识别类别。
这部分代码主要是在为使用YOLOv8模型做准备,它通过下载必要的字体和预训练模型文件,配置YOLOv8的环境。具体步骤如下:
步骤3:配置YOLO环境&训练模型
配置环境
!mkdir -p /root/.config/Ultralytics/
!wget http://mirror.coggle.club/yolo/Arial.ttf -O /root/.config/Ultralytics/Arial.ttf
!wget http://mirror.coggle.club/yolo/yolov8n-v8.2.0.pt -O yolov8n.pt
!wget http://mirror.coggle.club/yolo/yolov8n-seg-v8.2.0.pt -O yolov8n-seg.pt
详细说明:
- 创建目录:
!mkdir -p /root/.config/Ultralytics/
该命令用于创建一个名为 /root/.config/Ultralytics/ 的目录,-p 参数确保如果父目录不存在时自动创建它。这是 YOLOv8 所使用的默认配置路径,用来存储配置文件、字体文件等。
- 下载字体文件:
!wget http://mirror.coggle.club/yolo/Arial.ttf -O /root/.config/Ultralytics/Arial.ttf
该命令使用 wget 工具从指定的 URL (http://mirror.coggle.club/yolo/Arial.ttf) 下载字体文件 Arial.ttf,并将其保存到 /root/.config/Ultralytics/Arial.ttf 路径下。
Arial.ttf是用于渲染检测结果时的字体文件,通常YOLO模型在推理阶段输出带有标签的图片时需要使用字体文件来显示物体类别和概率等信息。这个步骤确保系统有字体文件可用。
- 下载YOLOv8n模型权重文件:
!wget http://mirror.coggle.club/yolo/yolov8n-v8.2.0.pt -O yolov8n.pt
这一步下载的是YOLOv8n(YOLOv8 “nano” 版本)的预训练权重文件,文件名为 yolov8n-v8.2.0.pt。-O yolov8n.pt 指定将下载的文件保存为当前目录下的 yolov8n.pt 文件。
- 这个权重文件是YOLOv8模型的基础模型参数,用于加载预训练模型,从而加速训练或直接用于推理。
YOLOv8n是 YOLOv8 的 “nano” 版本,体积小且推理速度快,适合资源受限的设备。
- 下载YOLOv8n-seg模型权重文件:
!wget http://mirror.coggle.club/yolo/yolov8n-seg-v8.2.0.pt -O yolov8n-seg.pt
这一行命令下载的是YOLOv8n-seg模型的预训练权重,文件名为 yolov8n-seg-v8.2.0.pt,并保存为 yolov8n-seg.pt。
YOLOv8n-seg是 YOLOv8 的分割模型版本(相对于普通的目标检测模型,这个模型还能进行实例分割任务)。同样,它是YOLOv8 “nano” 版本,体积小且运行高效。
总结:
这段代码的作用是为YOLOv8模型的训练或推理环境做准备。它主要做了以下几件事情:
- 创建了用于存储YOLO配置和字体的目录。
- 下载了YOLO模型输出图片时所需的字体文件。
- 下载了两个不同的YOLOv8模型权重文件:一个用于普通目标检测(
yolov8n.pt),另一个用于分割任务(yolov8n-seg.pt)。
这些步骤都是为了确保YOLOv8可以顺利加载预训练的权重文件并正常显示检测结果。
训练模型
from ultralytics import YOLO
model = YOLO("./yolov8n-seg.pt")
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=10, imgsz=640)
这部分代码的作用是使用 YOLOv8 模型进行训练,具体使用了实例分割任务的预训练模型 yolov8n-seg.pt。代码通过调用 Ultralytics 库,加载模型并开始训练。以下是详细的说明:
详细说明:
-
导入YOLO库:
from ultralytics import YOLO该行代码从
ultralytics库中导入了YOLO类。ultralytics是一个用于YOLOv8的官方Python库,支持目标检测、实例分割等任务。 -
加载预训练模型:
model = YOLO("./yolov8n-seg.pt")这一行代码将
yolov8n-seg.pt预训练模型加载到YOLO对象中。yolov8n-seg.pt是 YOLOv8 的实例分割模型预训练权重文件,nano版本体积较小,适合快速实验和资源受限的设备。yolov8n-seg.pt是预训练的模型参数,意味着它已经在一个大的通用数据集上训练过,具备了较强的基础特征提取能力。YOLO()构造函数会加载该模型,以便后续使用它进行训练或推理。
-
开始训练:
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=10, imgsz=640)这一行代码调用了
train方法来训练模型,指定了相关的训练参数:data="./yolo_seg_dataset/data.yaml":指定训练数据的路径,这个.yaml文件定义了训练集和验证集的路径以及类别信息。在之前的代码中已经生成过这个data.yaml文件。epochs=10:设置训练的轮数为10轮,也就是说,训练集的数据将被用来训练模型10次。更多的轮数通常可以提高模型性能,但也会增加训练时间。imgsz=640:指定输入图片的大小为640×640像素。YOLOv8的输入图片尺寸可以灵活调整,较大的图片尺寸通常能捕捉更多细节,但也会增加计算开销。
-
训练结果:
results会保存训练过程的结果,包括损失、精度等信息。训练过程中,模型会使用data.yaml文件中指定的训练集和验证集,基于预训练权重进行微调,以适应当前的数据集。
总结:
这段代码的主要目的是使用 YOLOv8n-seg(nano 版本的分割模型)在自定义的数据集上进行训练。具体执行的步骤如下:
- 导入
Ultralytics YOLO库并加载已经下载的yolov8n-seg.pt预训练权重。 - 利用定义好的数据集
yolo_seg_dataset/data.yaml,在自定义数据集上进行10轮训练,输入图片大小为 640×640 像素。
通过这个训练步骤,YOLOv8 模型将基于提供的训练集,逐步优化以在实例分割任务中表现得更好。
步骤4:预测数据集
from ultralytics import YOLO
import glob
from tqdm import tqdm
model = YOLO("./runs/segment/train/weights/best.pt")
# 获取测试图片路径
# 递归搜索 ./test_set_A_rename/ 目录下所有子文件夹中的图片文件
# `test_imgs` 这个列表会包含所有符合条件的文件路径,之后可以对这些图片进行批量处理。
test_imgs = glob.glob('./test_set_A_rename/*/*')
Polygon = []
for path in tqdm(test_imgs[:10000]):
results = model(path, verbose=False)
result = results[0]
if result.masks is None:
Polygon.append([])
else:
Polygon.append([mask.astype(int).tolist() for mask in result.masks.xy])
import pandas as pd
submit = pd.DataFrame({
'Path': [x.split('/')[-1] for x in test_imgs[:10000]],
'Polygon': Polygon
})
submit = pd.merge(submit, pd.DataFrame({'Path': [x.split('/')[-1] for x in test_imgs[:]]}), on='Path', how='right')
这段代码的作用是使用训练好的 YOLO 模型对测试集中的前 10000 张图片进行实例分割推理,提取分割的多边形信息,并最终将这些结果整理成一个数据框,方便后续提交或进一步处理。以下是具体步骤的详细说明:
详细说明:
-
初始化
Polygon列表:Polygon = []- 这是一个空列表,用于存储每张测试图片的分割结果。每张图片的分割多边形将被存储在这个列表中。
-
对测试图片进行推理:
for path in tqdm(test_imgs[:10000]): results = model(path, verbose=False) result = results[0] if result.masks is None: Polygon.append([]) else: Polygon.append([mask.astype(int).tolist() for mask in result.masks.xy])tqdm(test_imgs[:10000]):通过tqdm遍历前 10000 张测试图片,并显示进度条。test_imgs[:10000]是测试集图片的路径列表。results = model(path, verbose=False):使用 YOLO 模型对每一张图片进行推理。verbose=False表示关闭详细输出,只返回推理结果。results包含了模型在这张图片上检测到的所有物体及其分割结果。result = results[0]:由于每次推理返回的结果是一个列表,这里只取第一个结果results[0],这通常代表与输入图片path对应的推理结果。if result.masks is None:如果 YOLO 模型在图片上没有检测到任何实例分割的掩码(masks),就将一个空列表[]添加到Polygon列表中。else: Polygon.append([mask.astype(int).tolist() for mask in result.masks.xy]):- 如果检测到了分割掩码,使用
result.masks.xy提取掩码的多边形坐标。 mask.astype(int)将掩码坐标转换为整数类型,并将其转换为列表形式(tolist())。这种格式便于存储和后续处理。- 将每个多边形坐标列表追加到
Polygon列表中。
- 如果检测到了分割掩码,使用
-
创建提交数据框
submit:import pandas as pd submit = pd.DataFrame({ 'Path': [x.split('/')[-1] for x in test_imgs[:10000]], 'Polygon': Polygon })submit是一个 Pandas 数据框,包含两列数据:'Path':存储前 10000 张测试图片的文件名,通过x.split('/')[-1]提取图片路径中的文件名部分(不包括文件夹路径)。'Polygon':存储每张图片的分割结果,之前已经通过循环将所有图片的分割多边形信息存储在Polygon列表中。
-
合并所有测试图片路径:
submit = pd.merge(submit, pd.DataFrame({'Path': [x.split('/')[-1] for x in test_imgs[:]}), on='Path', how='right')- 通过
pd.merge将submit数据框与一个包含所有测试图片路径(test_imgs)的新的数据框进行合并。 - 这一步的作用是确保即使有些测试图片没有对应的分割结果,也会被保留在最终的结果数据框中。
how='right'指定右连接,意味着最终的结果中会保留所有的测试图片路径(即使在submit中没有对应的多边形信息)。- 合并后的
submit数据框中,如果某些图片没有分割结果,其对应的Polygon列会是空列表[]。
- 通过
总结:
这段代码的功能是:
- 使用训练好的 YOLO 模型对前 10000 张测试图片进行实例分割任务。
- 将分割结果转换为多边形坐标,并将每张图片的文件名和对应的分割多边形存储在一个 Pandas 数据框中。
- 最终将这个数据框与所有测试图片的路径进行合并,确保每张测试图片都在数据框中有对应的记录,即使没有检测到任何分割。
这个数据框可以用于提交分割结果,或者作为后续分析和可视化的输入